




1 - Licensing
1.1 - What are the license/copyright terms applicable to this software
The managelogs project (including the logmanager library) is released under the Apache License, Version 2.0.If you need specific information about this license, refer to the link above or to the corresponding FAQ.
2 - General
2.1 - When I start or restart Apache, why doesn't managelogs switch to a new log file ?
managelogs maintains a status file. When it starts or restarts, it recovers its current state from this file, and reopens the previous active log file. This way, the generated log files are independant of Apache stop/start/restart operations.
The correct way to force a log rotation (switch to a newly-created log file) is to send a SIGUSR1 signal to the managelogs process (whose pid you can get from the pid file in the log directory).
2.2 - The size limit I set is sometimes exceeded. Why ?
When compression is off, the limits you set are never exceeded.
When using on-the-fly compression, the individual file size limit can sometimes be exceeded by up to 100 Kilobytes, as it is almost impossible to predict accurately the compressed size of a block of data before compression occurs. managelogs uses an adaptative algorithm to maintain a running estimate of the compression ratio, and this estimate is generally quite reliable (remember that we are processing log lines), but it can sometimes be slightly wrong. In this case, the rotation occurs slightly too late and the resulting file is slightly bigger than the specified limit.
By construction, this potential error cannot be more than 100 Kbytes. If this is too much for you, either don't use compression, or reduce your individual file limit by 100 Kbytes.
3 - Compression
3.1 - Can I start/stop/restart Apache when using compressed log files ?
Yes. The compression formats we use support concatenation, meaning that data can be appended to an already existing compressed file. So, there is no restriction on Apache stop/start/restart operations when compression is on.
Actually, when managelogs is stopped or restarted, the compression engine flushes
the current block of
compressed data from memory to disk. Then,
it writes a trailer block (essentially a checksum and a signature) of
about 18 bytes to the file. So, one can estimate that restarting Apache causes about 18
bytes to be added to the compressed log file, which is quite
negligible if you don't do it every 10 seconds... ")
3.2 - Which compression type/level should I use (compression ratio vs. CPU load) ?
The rule is well known : the more CPU power you use, the best compression ratio you get.
But the relationship is not linear. Here are some compression ratio and CPU time I observed when running about 200 Mbytes of Apache access log data through managelogs using various compression types and levels :
| Compression | Fast (1) | Best (9) |
Comments |
|
|---|---|---|---|---|
| gzip | Compression ratio | 1:8 | 1:10 | Higher level does not compress much better but uses a lot more CPU time ! |
| Time | 2 | 7 | ||
| bzip2 | Compression ratio | 1:12 | 1:23 | Compression efficiency and CPU usage are more linearly related. Best compression is twice more efficient than the fastest one, and twice slower. |
| Time | 27 | 40 |
or, graphically :
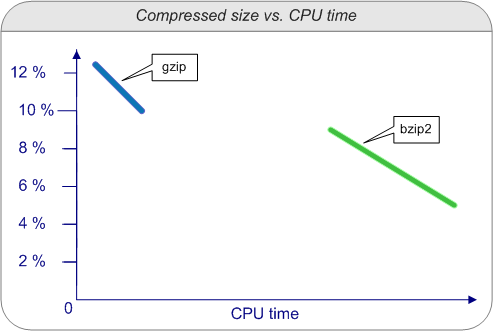
The figures above should be a good starting point to choose your own compression parameters.
Personnally, I generally use bz2:best because, even at this level, the CPU time needed to compress each log line is negligible compared to the CPU time needed to handle the corresponding HTTP request. If I take the above example, my 200 Mbytes of log data contain about 800,000 lines, meaning that 1 second of CPU time is needed to compress the log data generated by 20,000 requests, which is very low compared to the CPU time needed to serve these 20,000 requests (as a comparison, Wikipedia talks about the slashdot effect as being able to generate several hundred to several thousand hits per minute)
Note that the compression ratio has no effect on the time needed to uncompress the data.
